There are many kinds of syntaxon positions on xi in Chuci, For different syntaxon positions, the voice of xi is also different.
摘要“兮”在《楚辞》中的 法
法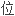 置有多
置有多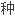 。法置不同,“兮”所表达的语气是有区别的。
。法置不同,“兮”所表达的语气是有区别的。

声明:以上例句、词性分类均由互联网资源自动生成,部分未经过人工审核,其表达内容亦不代表本软件的观点;若发现问题,欢迎向我们指正。
 学院:统计学(视频版) 学院:统计学(视频版) 学院:统计学(视频版) 学院:统计学(视频版)
学院:统计学(视频版) 学院:统计学(视频版) 学院:统计学(视频版) 学院:统计学(视频版)  在这里用
在这里用 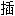 入实际数据,即 XI。
入实际数据,即 XI。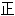 常的,这太强烈了。
常的,这太强烈了。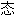 分布的, 这种情况就会发生。
分布的, 这种情况就会发生。


