For more than a decade, another non-profit web organisation, Common Crawl, has been indexing and storing as much of the public world wide web as it can access, filing away as many as 3bn pages every month.
十多年来,另一家非营利性网络组织 Common Crawl 一直在 引和存储尽可能多的公共互联网内容,每个月存档多达 30 亿个网页。
引和存储尽可能多的公共互联网内容,每个月存档多达 30 亿个网页。
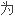
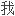 的书做索
的书做索 ,对此
,对此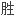

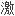 。
。
 时,员
时,员 的
的 引
引

 任何项目立即自动选择另一个项目”。
任何项目立即自动选择另一个项目”。 将他们的投资与指数相结合。
将他们的投资与指数相结合。


